
宝宝们是否对复杂的统计术语焦头烂额、束手无策?
众多学术指南、报告分析层出不穷,复杂的公式,晦涩的词句……想充电真的好难!
别急,点击下方视频学习你就可以快速掌握统计学的奥义啦~
本期课程:统计学这点「P」事
p 值是一个统计学上常用的参数,在很多科学文献以及临床研究结果中都活跃着 p 值的身影。然而,天天读文献的你,真的了解这点「p 事」吗?你会不会认为在某个对比 A 药和 B 药效果的实验里,相比 p<0.05,p<0.01 代表 A 药和 B 药的差异更大?
事实上并非如此,p 值体现的并不是 A 和 B 之间的差异大小,而是 A 和 B 之间有差异的可能性,具体来说是差异来源于抽样误差的可能性。比方说,某研究发现 A 药比 B 药的有效率高——这是因为 A 药确实比 B 药牛呢,还是恰好入选了用 A 药效果更好的患者?如果没了 p 值,这还真成了算不清的帐。
临床试验中通常说 p 值<0.05 代表两组间「具有显著性差异」,这实际上是在说,两组间的差异来源于抽样误差的可能性小于 5%。由于这个概率很小,我们一般认为这样的区别不大可能由抽样误差产生,而选择相信两组间确实有差异。
不难看出,0.05 是一个人为的设定。p = 0.049 和 p = 0.051 的两个结果比较起来,就好像是考试成绩 60 分与 59 分比较,只不过 60 分被人为定义为「及格」。为啥非要定 60 分?不要问我,因为考 59 分的时候我也很绝望啊。如果你是完美主义者,觉得 5% 的概率还是不够小,意外可能性要低于 1% 才好,设定「有显著性差异」的 p<0.01,当然也是可以的。
所以, p 值是人为定义的,未必一定是 0.05。看了下面的例子大家会更明白一些:在 FLAURA 研究中,OS 中期分析显示,奥希替尼对比标准治疗的 HR 为 0.63,p = 0.0068。p 小于 0.05 对吧,是不是可以断言具有统计学意义呢?非也,考虑到此时 OS 数据的成熟度只有 25%,经过计算,代表「统计学意义」的 p 值需要调整为 0.0015。如此看来,上述 OS 的差异还未达到显著,只能说奥希替尼具有 OS 获益趋势,还需继续观察。
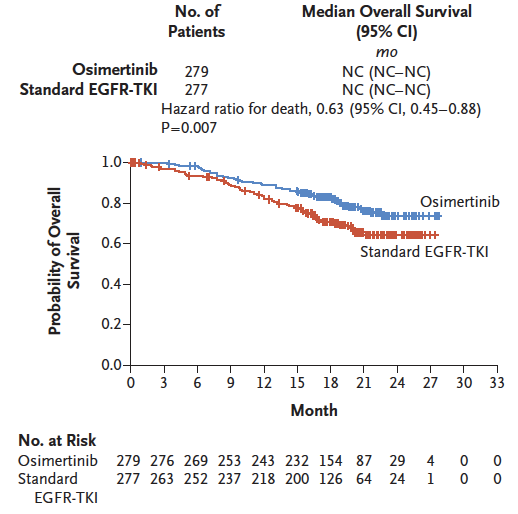
FLAURA 研究中奥希替尼对比标准治疗的 OS 中期分析(统计学差异需要 p<0.0015)
下面我们再举一个生动的例子!
从前有两个王国,都以盛产身材火辣的漂亮姑娘而著称。有一天两个王国的国王聊起哪国的姑娘身材更好,于是打了个赌。他们在各自的国家中分别「随意」选出 20 位姑娘,经测量,A 国的姑娘胸部平均为 C 罩杯;B 国的姑娘平均为 D 罩杯, B 国理所当然赢了这个赌。但 A 国的国王就是不服,觉得 20 位姑娘无法代表全国的身材水平,没准 B 国刚巧抽到了身材更劲爆的姑娘呢?那怎么办?还好 B 国的宰相懂得统计学,一番分析计算得出两国姑娘胸围差异的 p 值 = 0.03,并解释道,这说明两国姑娘身材相当,而 B 国运气好,正好抽到的都是大胸妹的概率有多少呢?只有 3% 而已。如此一来 A 国国王虽不甘心,也只好甘拜下风了。
从上面的视频中大家可能已经发现,计算 p 值的前提是「假设 A 与 B 没有差异」(如假设 A 国与 B 国姑娘的胸部大小相当)。而 p 值<0.05,说明所得结果由抽样误差产生的概率低于 5%,我们一般拒绝相信「A 与 B 没有差异」的原假设,并认为 A 与 B 存在差异——这就是所谓的「假设检验」。
归纳起来,p 值表示对比差异来源于抽样误差的可能性,当此概率小到一定值(一般采用 5% 即 p = 0.05)时,我们就会选择相信差异确实存在。
当然,在临床研究统计分析中,我们不光要看 p 值,更要关注试验设计、差异的大小、专业意义等诸多因素,来进行综合的科学推断。
更多内容推荐:
